
Abstract reasoning and conceptual generalisation in deep learning
Published:
In this blog post I will go over the problem of abstract visual reasoning; which has recently emerged as a challenging domain for machine learning tasks. Before I do that I will explain the issues with ‘conceptual’ generalisation in machine learning.
After that, I will explain the problem setting of Raven’s Progressive Matrices which serve as a test-bed for abstract reasoning ability, discuss two datasets released for machine learning research on this problem, go through a couple of the models with code in Pytorch and leave you with some open questions. Hopefully this blog post generates as much of an interest in this problem as it did for me while reading these papers. Let’s dive right in!
1. Conceptual generalisation
Generalisation has proven to be a very hard nut to crack for artificial intelligence. In simple terms, generalisation is the ability of a model to perform well on previously unseen data. It’s important to clarify here what we mean by unseen data. In your regular Machine Learning 101 class you’d think of this as the test split of the data whose training split your model has learned on. While this definition of ‘unseen data’ is most definitely true, we can expand on it in more conceptual terms, which leads to several ideas of generalisation:
Domain adaptation
When the test and train data are from different ‘domains’ then the problem of generalisation is referred to as domain adaptation. What does different domains mean? Think of it as having the training data and test data from different probability distributions:
\[\begin{aligned} \text{train data} \ X \sim P(x_1,x_2,...,x_n) \\ \text{test data} \ Y \sim G(x_1,x_2,....,x_n) \\ \end{aligned}\]How different can these distributions be? In most research use-cases they are not that different. For example take the case of images:

Image source: Sebastien Ruder’s blog
If you think of the underlying distribution to factored along a certain number of latent variables usually domain adaptation involves adapting to the change in distribution of one (or a few) of the latent variables:
\[\begin{aligned} \text{train data} \ X &\sim P(x_1,x_2,...,x_n) \\ \Rightarrow X &\sim p_1(x_1)p_2(x_2)...p_k(x_k)...p_n(x_n) \\ \text{test data} \ Y &\sim G(x_1,x_2,....,x_n) \\ \Rightarrow Y &\sim p_1(x_1)p_2(x_2)...g_k(x_k)...p_n(x_n) \\ \end{aligned}\]In the case of the bike examples shown above think of $x_k$ as a variable representing backgrounds where $p_k$ is a distribution of clear backgrounds and $g_k$ is a distribution of cluttered backgrounds. In several applications this change in distribution can be modelled simply as a change in the mean of $p_k$ or a similar small change.
Compositional generalisation
A lot of human intelligence is compositional in nature. In order to explain compositionailty let me give you an example of the steps I followed when I had to travel from Gorakhpur, India to Guelph, Canada for grad school:
- Drive(my house -> Gorakhpur airport)
- Flight(Gorakhpur->Delhi)
- Switch terminals(Delhi domestic->Delhi international)
- Flight(Delhi->Frankfurt)
- Switch terminals(Frankfurt arrivals->Frankfurt departures)
- Flight(Frankfurt->Toronto)
- Drive(Toronto airport->Guelph)
You’ll notice that several basic steps (driving, catching a flight, changing terminals) are brought together in a certain way in order to complete a seemingly daunting task of travelling over 10000 kilometers from India to Canada (which, by the way, I had never done before)! This is the idea behind compositional generalisation: being able to understand previously seen basic concepts when they are brought together in novel unseen ways. This is demonstrated in the image below. You might’ve never seen such a vehicle before but by putting together its components you could easily tell that it’s a vehicle.

Image Source: Lake and Baroni
In terms of the original domain adaptation formulation, we can think of compositional generalisation as the case where we are expected to perform zero-shot generalisation (test case previously unseen) to an example from a distribution where the ‘semantics’ of the underlying variables remain the same.
Systematic generalisation
Systematic generalisation can be seen as a superset of compositional generalisation. Besides generalising to novel compositions of previously seen concepts, we would like our models to generalise from few->more instances of the same concepts and vice versa. While the difference between systematic generalisation versus compositional generalisation is not very clear in the artificial intelligence community there seems to be a lot of consensus that the ability of AI models to perform such generalisation is going to be at the core of more ‘general’ artificial intelligence models.

Image Source: Bahdanau et al
2. Abstract Reasoning and Raven’s Progressive Matrices
Raven’s Progressive Matrices [1] (or RPMs for short) are test of visual intelligence administered in humans. An RPM consists of a 3x3 panel of images with the bottom-right image missing. The aim is to follow the abstract pattern used in other rows/columns to fill out this image. For example, in the RPM displayed below the pattern is that the darkened inner quarter of the images in each row rotates clockwise.
 |
|---|
| Image source: Wikipedia |
While they appear quite simplistic at first glance, these tests have been shown to be strongly diagnostic of abstract verbal, spatial and mathematical reasoning ability. They have been found to be good measures of fluid and general intelligence in humans.
RPMs offer an interesting challenge for artificial intelligence. There are several levels of reasoning involved in solving an RPM-style task: sometimes parallely and other times heirarchically. For the example shown, these reasoning steps could have been:
- Relational reasoning:
Q: What part of an image panel is involved in the pattern? (A: a quarter)
Q: How is it changing across the columns? (A: moving clockwise) - Analogical reasoning:
Q: How is the dark square in the first row similar to the dark pie-shape in the second row? (A: they both form a quarter of the shape in the full panel) - Spatial reasoning:
Q: How does the change in the first column to the second relate to the change in second row to the third? (A: they represent a 90° rotation to the right)
You might’ve used some (or all) of these reasoning arguments to conclude that the bottom panel should be the diamond rotated in such a way that it’s rightmost square is dark. The question is: Can deep learning do the same?
2.1 DeepMind’s PGM dataset
In their paper “Measuring abstract reasoning in neural networks” [2], Barrett, Hill and Santoro released a machine-learning scale RPM dataset. This dataset (dubbed Procedurally Generated Matrices or PGM for short) contained a whopping 1.4 million RPM problems. An example of such a problem is shown below:
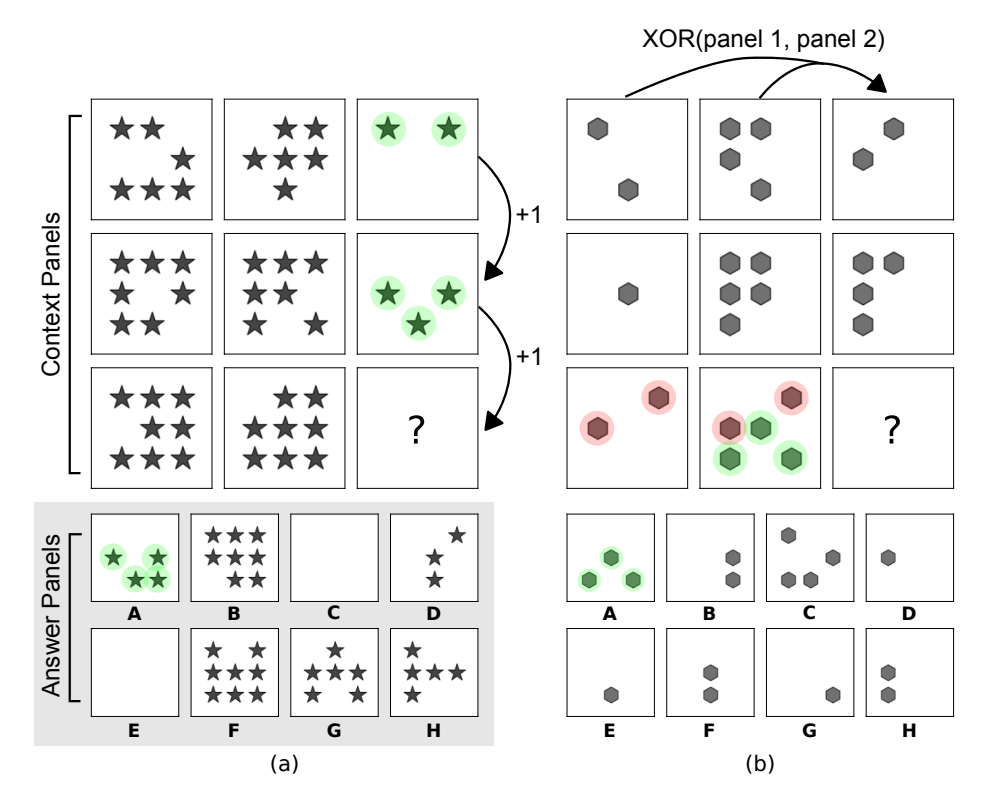
Image Source: Barrett et al
References
[1] Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. “Human-level concept learning through probabilistic program induction.” Science 350.6266 (2015): 1332-1338.
[2] Lake, Brenden, and Marco Baroni. “Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks.” International Conference on Machine Learning. PMLR, 2018.
[3] Bahdanau, Dzmitry, et al. “CLOSURE: Assessing Systematic Generalization of CLEVR Models.” arXiv preprint arXiv:1912.05783 (2019).
[4] Raven, J. C. et al. Raven’s progressive matrices. Western Psychological Services, 1938.
[5] Barrett, David, et al. “Measuring abstract reasoning in neural networks.” International Conference on Machine Learning. 2018.
[6] Zhang, Chi, et al. “Raven: A dataset for relational and analogical visual reasoning.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.